Everything that happened in the synthetic data space in 2022
For an up-to-date directory of synthetic data solution, check https://syntheticdata.carrd.co/
Over the past year, we saw notable growth in the synthetic data space and exciting market shifts. In this article, I’ve compiled updates from a year of market monitoring. Read about the new players, developments, and perspectives on how the ecosystem evolved.
Synthetic data new players and market analysis
When I published the 2021 synthetic data landscape post, there were 67 vendors:
- 28 structured synthetic data vendors,
- 10 synthetic test data vendors,
- 6 open source vendors,
- and 29 unstructured data vendors.
One year later, we’re looking at a new picture:
We’re adding 28 vendors to the map, bringing it to a total of 97 companies commercializing synthetic data products and services.
We’re adding 31 vendors to the map, bringing it to a total of 100 companies commercializing synthetic data products and services. 5 companies closed down, and I took the open-source solutions out of this map. Head to this article to browse the updated list of synthetic data companies.
In the structured data space, we have 17 new names if we count privacy-preserving and test synthetic data offerings together. These vendors are Aindo, Neutigers, Nuvanitic, Syntonym, Datacebo, Particle Health, Scale Synthetic, IvySys, Yet Analytics, DatProf, Esito, Accelario, Validata, Avo Automation, Broadcoam, Smart Data Foundry, Clearbox AI, Bulian AI.
The number of synthetic test data vendors has been booming. However, the companies interchangeably use the term “synthetic data”. Sometimes the vendors do rule-based simulated data (fake data), while others offer AI-generated synthetic data. In any case, the technology is rising, boosted by fewer privacy constraints for those developing fake data. It also builds on existing open-source bricks that streamline new capacity developments. Thus we’re now seeing DataOps, test data, or Data Automation software vendors adding synthetic or fake data capabilities to their solution offering, doubling down on the argument of privacy for test data.
Additions to the list in the unstructured data space include Infinity AI, vAIsual, Mirage Vision, Omniverse™ Replicator, Scale Synthetic, Datagrid, Kroop AI, Indika AI, CNAI, Deci, Alethea AI, Syntric AI, SBX Robotics.
Bitext appeared in the less dynamic area of synthetic text data and Deepsync in the synthetic audio space.
We continue witnessing a strong development of unstructured synthetic data solutions. A few characteristics explain the faster development of this side of the market:
- the maturity of the use-cases such as computer vision training,
- the availability of supporting technology such as image modeling software and games engines,
- and the greater adoption of the technology in fast-growing industries such as automotive, retail, or video games.
Finally, the open source landscape expanded. We recently surveyed the open source ecosystem, and the list of tools added up to 20.
Strategic developments
The market shifts were the most exciting part of the market development. Below I am presenting 6 trends observed over the last few months in the synthetic data space:
- Funding: investments have been a key element in the development of companies in recent months. They amounted to at least $325 million in the last 18 months.
- Pure-players specialization: Pure-players specialization: after having known a homogeneous market for the first years, vendors are accentuating the differentiation with positioning choices on use-cases or industries.
- Moving away from a pure product industry: we are seeing the arrival of services and new business models in an industry that until now has been very focused on a product-oriented offer.
- In-house development: synthetic data is no longer the prerogative of pure players. In recent months, large companies have announced the development of in-house synthetic data capabilities.
- Key partnerships: in parallel to internal developments of synthetic data capacities, other large companies have taken the path of partnerships, creating deals between pure players and big tech or specialized companies.
Funding
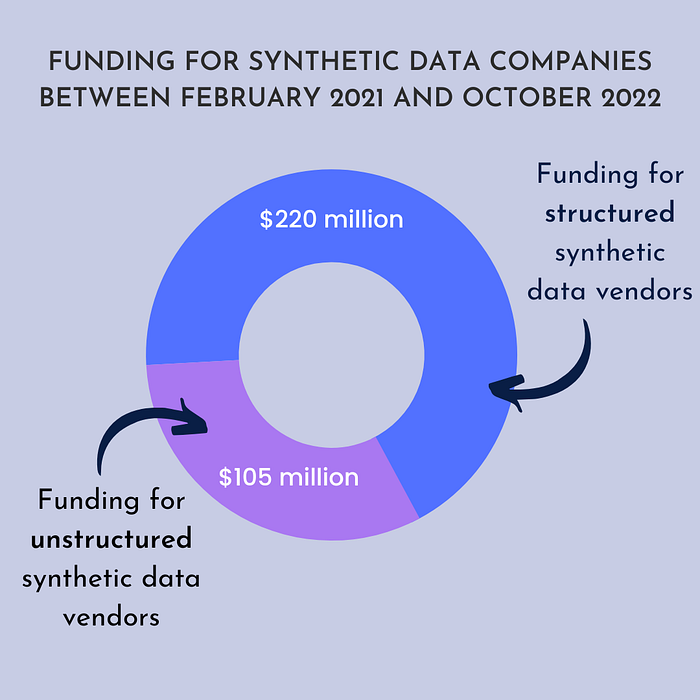
The total of publicly-known funding for synthetic data companies reached $328 million in the last 18 months.
The total of publicly-known funding for synthetic data companies reached $328 million in the last 18 months. That’s $275 million more than in 2020. Structured synthetic data companies raised:
- Diveplane got a $25 million series A funding in September 2022
- CNAI raised $4.1 million in July 2022
- MDClone raised a $63 million series C funding round in March 2022
- Mostly AI raised $25 million in a Series B funding round in January 2022
- Syntegra closed a $5.6 million seed financing round in January 2022
- Aindo raised €2.8 million in December 2021
- Gretel.ai closed a $50 million Series B funding round in October 2021
- YData raised €2.33 million in October 2021
- Tonic closed a $35 million Series B funding round in October 2021
- Octopize raised €1,5 million in September 2021
- Datomize raised a $6 Million seed funding round in February 2021
Unstructured synthetic data companies received:
- $17 million series A funding for Synthesis AI in April 2022
- $3.5 million seed funding for Neurolabs in May 2022
- $50 million series B funding for Datagen in March 2022
- $13 million series A funding for Synthetaic in March 2022
- $21 million series A funding for Deci in October 2021
- And $3.25 million for MindTech in July 2021
Pure-players specialization
There were two significant shifts for structured synthetic data vendors: industry specialization and use-case broadening with synthetic data for testing. Regarding industry specialization, the following companies specialized or positioned on a market niche:
- FinCrime Dynamics presented Synthesizer®, a tool designed for the finance industry and fraud detection use cases.
- Nuvanitic launched Nuvanitic IntelliHealth TM, a solution for the pharma industry specializing in synthetic clinical trial data.
- VAIsual announced its synthetic data offer for the B2B IP licensing market.
- IvySys launched a synthetic data generation tool for synthetic threat transactions.
- Smart Data Foundry researches synthetic financial datasets to fraud fighting and financial institutions in the UK.
Additionally, in the synthetic data space, historical pure players broadened their use cases from privacy to test data generation. This closes the gap between the privacy-focused and the vendors historically focused on synthetic test data. For example:
- Mostly AI announced synthetic data for testing
- Syntho advertises test data use-cases
- Synthesized communicates on synthetic data test
The traction for this market segment, where synthetic data is sold as an alternative to test datasets or real data in testing environments, is growing too, as evidenced by the many references to synthetic data in job offers for QA engineers.
On the unstructured data side, the focus on applications is also evolving. As pointed out by a Reddit user, it’s slowly moving from the rather popular area of domain randomization, which supports the creation of multiple variations of scenarios or images, to applications that build more realistic-looking images, like synthetic brain imagery.
Services and new business models
While most companies have been developing software solutions since 2018/2019, we started to see services and marketplaces around synthetic data arrive on the market. APIs, marketplace and self-service synthetic data services might be ideal to meet more ad hoc needs and could accelerate technology adoption through streamlined testing processes.
Some companies have banked on simplified and quick access to synthetic data tools to boost adoption. As a result, a couple of freemium and self-service models have sprung up:
- Clearbox AI launched a synthetic data on-demand service.
- Mostly AI launched a freemium Saas access to its software in July.
Interestingly, when it comes to self-service structured synthetic data, the offerings requiring data submission face the same data processing constraints that drove people to privacy-preserving synthetic data in the first place. To use personal data for such on-demand services, customers must have a legal basis and consent from the data subjects. As a possible answer, we’ve seen the development of the combinations of Privacy-Enhancing Technologies (PETs).
- Cybernetica announced in April that it was working on a service prototype for data synthesis in trusted execution environments (TEE).
While dataset sales were common for unstructured synthetic data vendors, structured players also got into synthetic dataset sales. For example, GeoTwin proposes synthetic population datasets. With a different access model but a similar intention, synthetic data APIs and marketplaces also emerged in the past months:
- Infinity AI announced the launch of Infinity API in March 2022.
- Syntegra announced the availability of its API in August 2022.
- Particle Health introduced a Sandbox API to get synthetic medical records.
- Alethea AI announced the development of a decentralized synthetic content network for AI-generated media.
Just as the lack of data is a challenge for many companies, the lack of training data to generate synthetic data is also problematic. Today, there is a clear added value in proposing synthetic data pools that combine the original data of several enterprises. However, even if we see the first APIs and marketplaces arriving, the legal, corporate, and technical barriers to these offers make them still rare, especially in Europe.
In-house development
There have been two types of development for synthetic data capabilities. On one side, privacy software vendors focusing on other protection techniques are now adding synthetic data capabilities to their toolbox to broaden the privacy technology offering for their customers.
On the other side, big tech and large companies are looking to develop their own synthetic data capabilities. Usually, when they develop structured synthetic data tools, they aim to improve data access and flow within departments and with their partners. For unstructured data, most cases have been around supporting the development of ML learning models.
Privacy software vendors adding synthetic data capabilities:
- Norwegian software vendor Esito included synthetic test data generation in its g9 privacy product.
- Test data and privacy software solution vendor DatProf added synthetic data capability to its test data offering.
Large companies have already announced that they are using or developing technology or have shown intentions to do so. Compared to last year, many more big players have taken this route. Among notable unstructured data capability development, we find, for example:
- Snap Inc: the company behind Snapchat published a blog in September 2022 explaining how it works with synthetic data to boost the development of its ML models.
- NVIDIA: the technology company announced in October 2021 the launch of its synthetic data generation engine for deep neural networks training.
- L3 Harris: the sensor manufacturer announced in April 2022 its new offering of synthetic imagery data.
- Siemens: in January 2022, the tech company introduced SynthAI, the online synthetic data service from Siemens Digital Industries Software.
- Toyota: the automotive giant has been exploring synthetic data for computer vision, notably through its Toyota Research Institute.
- Uber: in its AI Labs, the company develops its own Generative Teaching Networks models.
- Microsoft: the tech company is also undertaking research into synthetic data with projects such as Face Synthetic or the Global Synthetic Dataset, a synthetic dataset on human trafficking developed in collaboration with the International Organization for Migration (IOM).
- Amazon announced in June 2022 that synthetic data generation was now possible in their data labeling solution Amazon SageMaker.
- Peloton uses synthetic data to improve its computer vision systems.
There were fewer communications about in-house developments of structured synthetic data capabilities. One of the reasons could be the complexity and lower technology maturity, which, as we’ll note in the next section, is compensated by more partnerships.
- Scale AI: the AI company announced the availability of a synthetic data solution, Scale Synthetic.
- Microsoft: the company AI Lab is working on structured synthetic data capability and built the Synthetic Data Showcase, an open-source tool from MSFTResearch.
- Palantir: the company mentioned synthetic in the documentation on the Foundry Software. The page is no longer available but still visible in Google SERP.
Many big tech companies’ research departments have been actively hiring synthetic data engineers or privacy professionals these past months. It was notably the case for Apple’s Synthetic Data Group, TikTok Privacy Innovation (PI) Lab, or Mastercards.
Key partnerships and acquisitions
Finally, the last months saw a multitude of partnerships between synthetic data vendors and big tech or specialized companies. Where companies couldn’t (or wouldn’t) build, they bought and signed deals. The market is consolidating. Examples of deals in specialized industries:
- Replica analytics partnered with a medical research open platform OSRC in October 2021. In January 2022, they announced their acquisition by health analytics company Aetion.
- Synthetic health data provider Syntegra also announced a partnership with a health tech company, InterGen Data, in September 2022.
- In March 2022, Mindtech and data collection tech company Appen announced a $3.7 Million partnership.
- Twitter teamed up with OpenMined to develop a synthetic dataset of its data analysis and share it in January 2022.
- In December 2021, Meta acquired AI Reverie to support the development of its Metaverse.
- Gretel partnered with health company Illuma in December 2021 to advance the development of highly requested genomic synthetic data.
- Google Cloud and health insurance company Anthem partnered to produce synthetic fraud transactions in May 2022.
- SAS Netherland and Syntho started a partnership back in November 2021.
- Synthesized solidified its partnership with German bank Deutsche Bank in September 2022.
Ecosystem development
A few signs are worth noting in ecosystem development. The technology receives increasing interest from regulators who have become aware of the need to set up a legal framework around them. Until now, no European actors have taken the initiative to produce recommendations on using technologies for data protection purposes. However, several of them have launched research to improve the understanding of the market and the needs of companies. The UK’s ICO launched a consultation on the draft of its guidance on anonymization, pseudonymization, and PETs.
Public institutions also show increasing interest, with calls for projects and public consultations. For example, the UK’s financial authority issued a call for input on 30 March on synthetic data. The EBSP undertook to monitor the development of these technologies through its TechSonar initiative, including a track for synthetic data. In Asia, the Hong Kong Monetary Authority launched in November 2021 a RegTech lab to further investigate, among other things, the development of synthetic data for Anti-Money Laundering.
Market analyses are flourishing everywhere. With research from major groups such as Gartner, Forester, or CBinsights at the top of the list, announcing a wide adoption of synthetic data in the years to come. Prophetic announcements or reality? In any case, these firms contribute significantly to influencing buyers, and their position impacts the development of the synthetic data market.
Finally, communities are gradually emerging, gravitating around the open source space, where people seek support in developing their tools. For example, the Synthetic Data Vault Slack space now counts 700 people. The Open SD was created to share educational analytic tools and resources around OpenSDPsynthR.
But synthetic data communities are steamed not only from the open source world, as vendors also try to generate momentum through communities that will support larger market education efforts.
- Synthesis AI launched Open Synthetics in April 2022, an open community for creating and using synthetic data in computer vision and machine learning.
- YData created the Synthetic Data’s Community
- GenRocket announced in June the launch of GenRocket Community, a community focused on test data generation.
From an insider perspective, the market started to reshape in the last few years. We now see strategic trends emerge. Startups and products keep coming as the mainstream news shares predictions about a synthetic future, and big techs send maturity signals through development and partnerships. There is of course much more to unpack: looking into the compliance challenges behind synthetic data, the use-cases and customer adoption, or the current technical limitations. But I’ll keep that for next post.
Let me know your thoughts about this article. Have you noticed other developments? Do you think the future is synthetic? Hit me up here or on LinkedIn and Twitter with your comments.
